Inspired by a recent Twitter conversation with @DrLukeOR, I thought I’d write a quick blog post about how I keep myself organised. This post starts with a short caveat that the latest version of my preferred software Evernote has a significant (but hopefully temporary?!) loss of some key functions as they rebuild it from the ground up to be more stable; I’ve downgraded to version 6.25 for now. As always, there is an inertia once your work processes are embedded in a particular tool but my organisational technique would work on many similar platforms and I’m keeping an eye on both Notion and Roam to see how their tools mature.
Getting Things Done (GTD) was originally created by David Allen back when file cards and label printers were the height of technological sophistication. It looks like his original book has been updated since I read it – I imagine it’s still the quick read that gives you a good grounding in the technique. A Google of the initials GTD will open the door to a world of enthusiasts who’ve taken his simple and effective ideas and are sharing their own personalised implementations.
My own GTD flavour has been refined and improved over more than a decade of use and gives me the right balance between the “overhead” of adding and organising my tasks, and the true value of a good system – never losing an idea and instantly finding the exact right task to do at the right time.
GTD centres around the concept of clearing every task out of your head into a reliable system; your brain is a terrible place to accurately remember lists of stuff. I have an “_Inbox” folder where everything gets thrown. I then have a set of nested “_Tasks” folders that store all my GTD tasks. Why the underscores? It keeps my GTD folders at the top and typing an underscore instantly shows only the GTD folders. Within my tasks folder, there are:
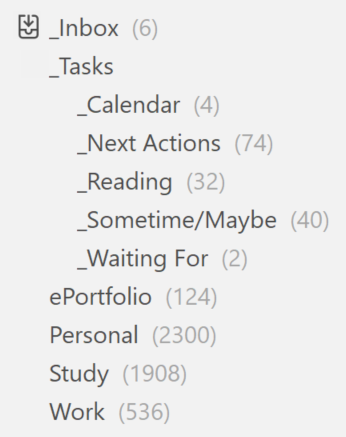
- “_Next Actions” – where the bulk of my tasks end up
- “_Calendar” – tasks with reminders on them that can only be actioned when they reach that reminder date (to stop me seeing them before I can do them)
- “_Sometime/Maybe” – aspirational ideas or goals I don’t want to lose but won’t be actioning in a hurry.
- “_Waiting For” – when I’m waiting on someone else for something before I can carry on – it can be good to add reminders to these as well.
- “_Reading” – articles I need to read – not a typical GTD folder and could probably be a tag instead but I’ve found it easier to keep them separate
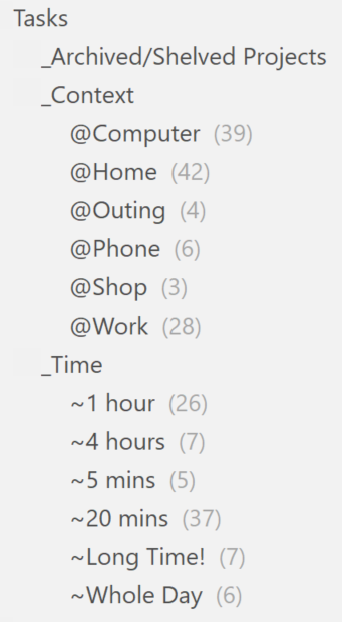
Next, I have GTD tags – this is one of the first areas where the real power of the tool kicks in – I can organise anything into an appropriate grouping with a few keystrokes:
- Context tags start with an “@” – note that they all start with a different character.
- Time tags start with an “~” – again, make each one start with a different character to speed things up when tagging with keystrokes.
- Current Projects (not shown) start with a “.” – when I’m done with them, I drop the “.” and move the tag under the Archived/Shelved Projects grouping.
As an example, if I see an article I want to read, I hit the keystroke shortcut on the Evernote Chrome Extension, and simply choose the “_Reading” folder; if I’m feeling enthusiastic, I can tag it with a current project by hitting “.” and the appropriate project. Similarly, if I think of a task I need to do when out and about, I click a single shortcut on my Evernote Android Widget and type in a few words or take a picture and it will automatically save to my “_Inbox”. I will tend to tag it on the laptop as it’s slightly quicker there, and drop it into the “_Next Actions” folder.
That’s it! Building my task list is simply about clearing everything out of my brain as soon as it arrives there and, when I’m ready, adding a few tags to organise it a little. Finding the right next task to action is also easy – I just filter them to my context and the time I have*. No more endless overhead and guilt associated with the creation of overly optimistic daily task lists that I never quite complete.
As a final thought – while people might choose to implement GTD in a tool that is more purely designed for task management such as Trello or ToDoist, I find the power of using Evernote as the repository for absolutely everything means I’m not needing to maintain my “list of things I’m doing” in more than one place; the “Write notes on Wednesday’s meeting” task becomes the “Notes on Wednesday’s meeting” project resource when I’ve finished the task.
*I confess, I’ve found I slightly hack this by the addition of a simple “#” as a tag to highlight stuff I want to do urgently. You can use “Shortcuts” to pin searches, tags and folders to find things like this even more quickly.
